PIGINet predicts the feasibility of a task Plan given Images of objects, Goal description, and Initial state descriptions.
It reduces the planning time of a task and motion planner by 50-80% by eliminating infeasible task plans.
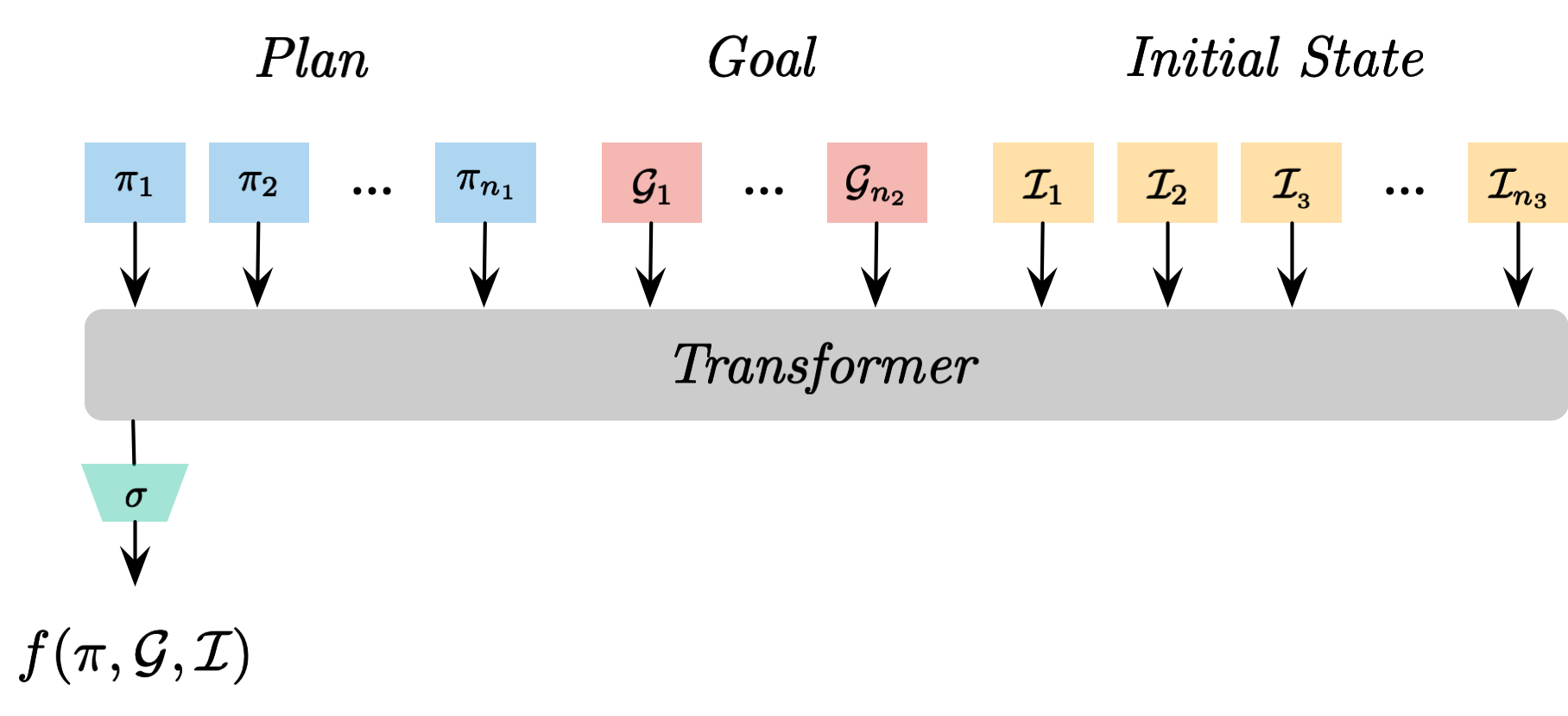
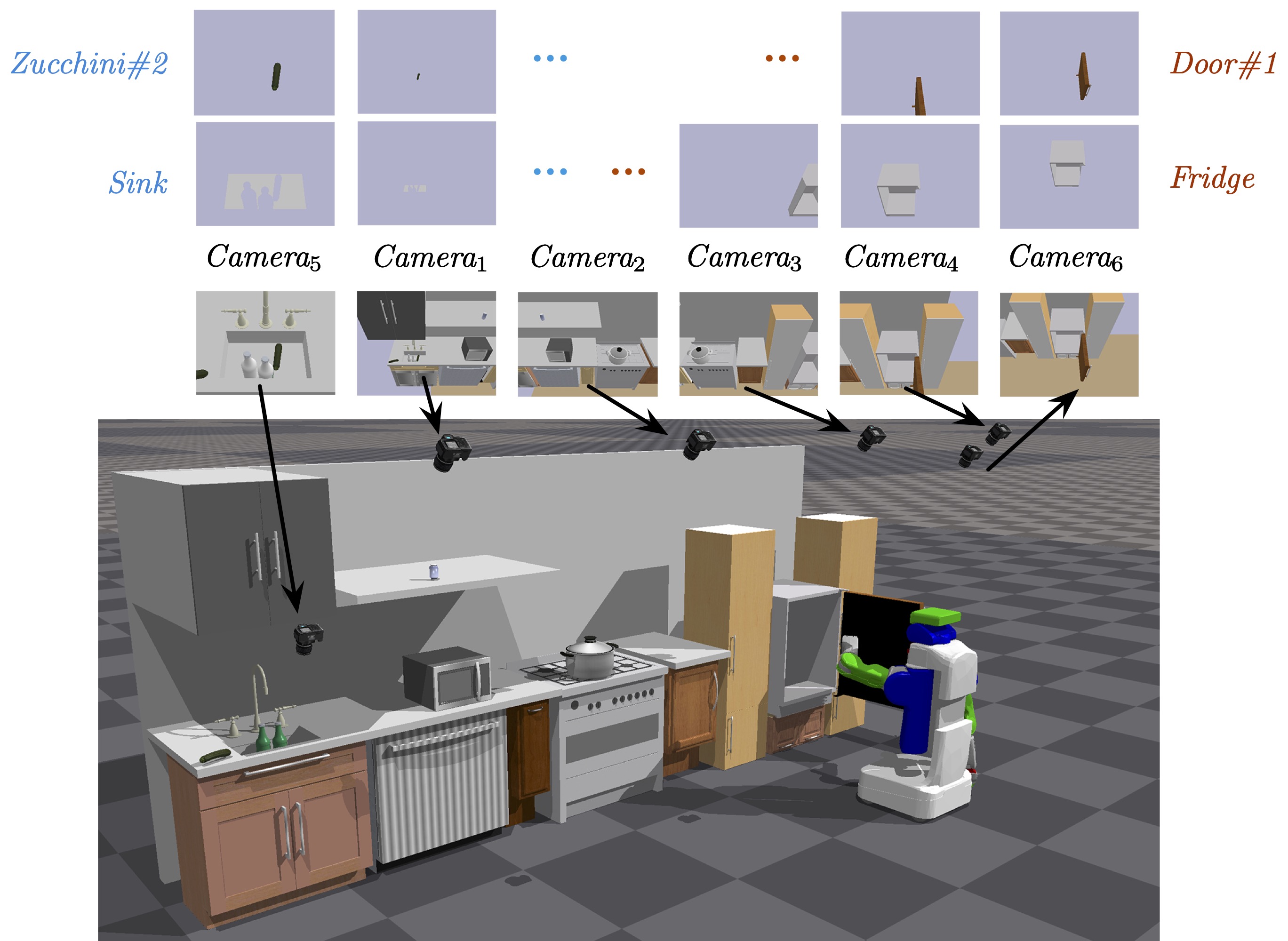 We present a learning-enabled Task and Motion Planning (TAMP) algorithm for solving mobile manipulation problems in environments with many articulated and movable obstacles. Our idea is to bias the search procedure of a traditional TAMP planner with a learned plan feasibility predictor.
We present a learning-enabled Task and Motion Planning (TAMP) algorithm for solving mobile manipulation problems in environments with many articulated and movable obstacles. Our idea is to bias the search procedure of a traditional TAMP planner with a learned plan feasibility predictor.